初识Redis
认识NoSQL

SQL的全称是结构化查询语言(Structured Query Language),是一种用于关系型数据库的查询语言
NOSQL的全称是Not Only SQL,不限于SQL,也可以说是非关系型数据库,说明它于传统的SQL有所不同,而Redis正是一种NOSQL,接下来看一下两者的不同
2、相关业务对数据安全性、一致性要求较高
2、对一致性、安全性要求不高
3、对性能要求较高
NOSQL的非结构化类型主要有:
NOSQL没有统一的SQL语句
认识Redis
Redis诞生于2009年,全称是Remote Dictionary Server,远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
安装Redis
这里简单讲述一下Linux中Redis的安装过程
Redis的官方网站:https://redis.io/
因为Redis是基于C语言编写的,因此需要安装Redis所需要的gcc依赖
bash
yum install -y gcc tcl在Redis官方网站下载好安装包,并上传到Linux上,目录看自己喜好,上传完成后进行解压
bash
tar -zxvf redis的文件名进入redis的安装目录
bash
cd 解压完成后的redis目录运行编译命令
make是编译,make install是安装
`make & make install`是编译并安装
bash
make & make install默认的安装路径就是在`/usr/local/bin`目录下
该目录以及默认配置到环境变量,因此可以在任意目录下运行这些命令
默认启动
bash
redis-server启动后,你会发现你无法连接客户端,因为服务端已经建立连接了,如果你想连接客户端,你得重新打开一个页面建立客户端的连接,我们发现这样很麻烦,所以我们需要让它后台启动
指定配置启动
在我们之前解压的redis安装包下,有一个redis.conf的配置文件,我们先将这个文件备份一份
bash
cp redis.conf redis.conf.bck然后对redis.conf进行修改
bash
vi redis.confRedis的常用配置
properties
# 监听的地址,默认是127.0.0.1,会导致只能在本地访问,修改为0.0.0.0可以在任意IP进行访问
bind 0.0.0.0
# 守护进程,修改为yes后即可在后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 123456Redis的其他配置
properties
# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号为0~15
databases 1
# 设置redis能够使用的最大内存
maxmemory 512mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"指定配置文件启动,如果在redis-server命令所在的文件夹下启动的,则不需要指定,默认为当前目录下的redis.conf配置文件,如需指定,可使用下面的代码
bash
redis-server redis.conf查看redis进程
bash
ps -ef | grep redis停止redis进程
bash
kill -9 redis对应的进程号默认自启动
Redis客户端
Redis命令行客户端
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下
bash
redis-cli [options] [commonds]options是可选项,常见options有:
commonds是Redis的操作命令,例如:
`ping`:与redis服务做连通测试,服务端正常会返回`pong`
不指定commonds时,会进入`redis-cli`的交互控制台
Redis图形化客户端
Redis图形化客户端是一个GitHub上的大神出的,所以需要在GitHub上下载
地址如下:https://github.com/MicrosoftArchive/redis/releases
这里就不讲关于Redis图形化客户端的安装了,都很简单,我们讲讲如何使用
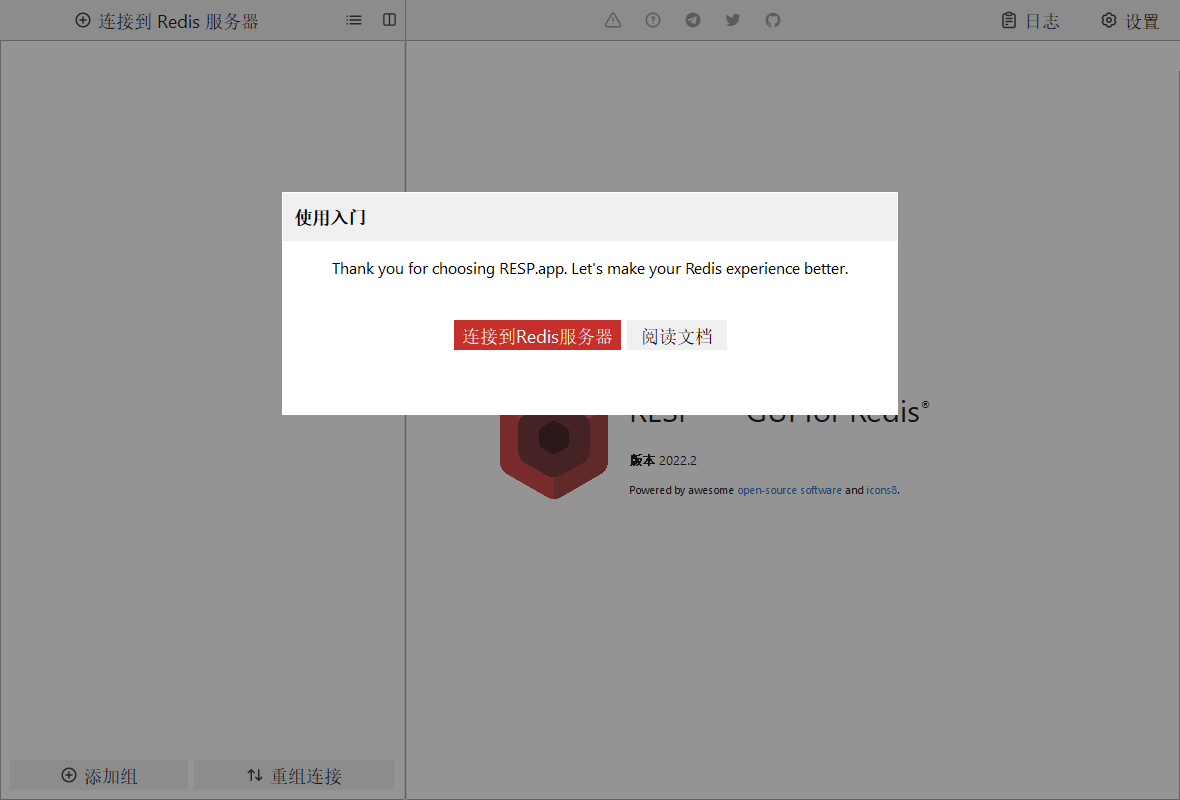
打开后的页面如上图所示,我们单击`连接到Redis服务器`
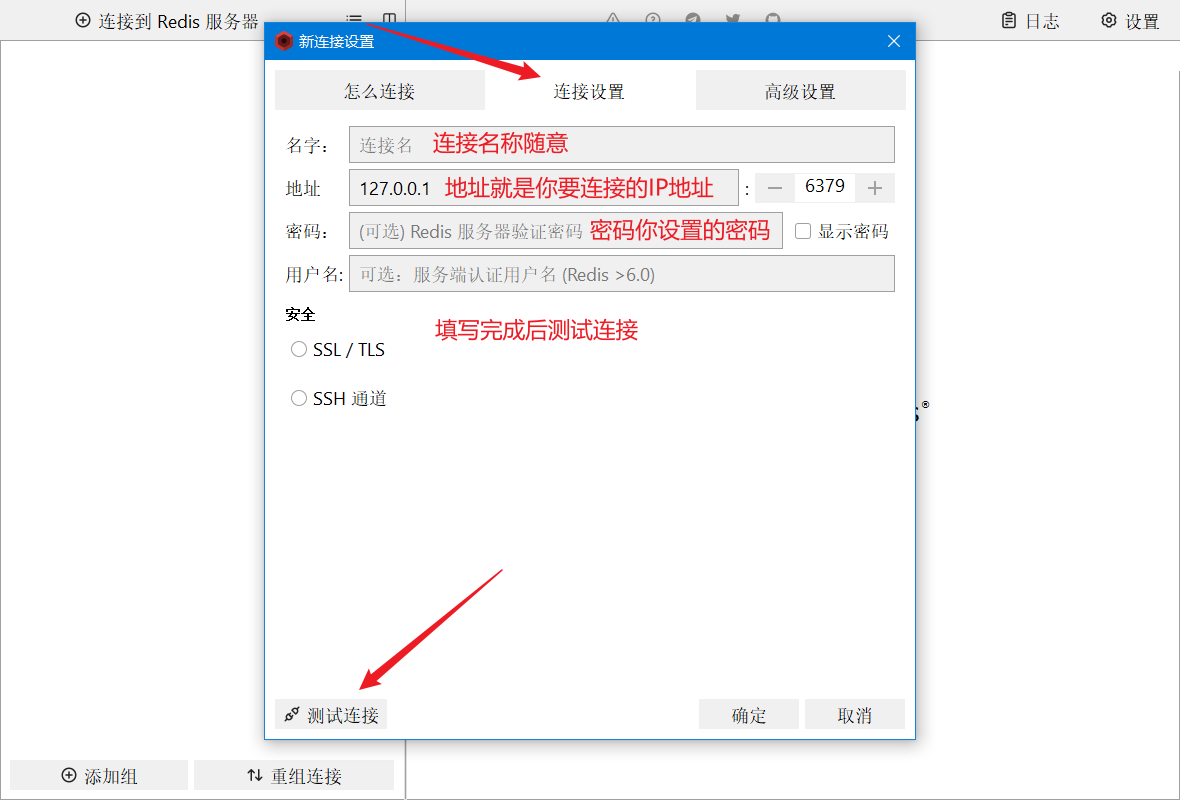
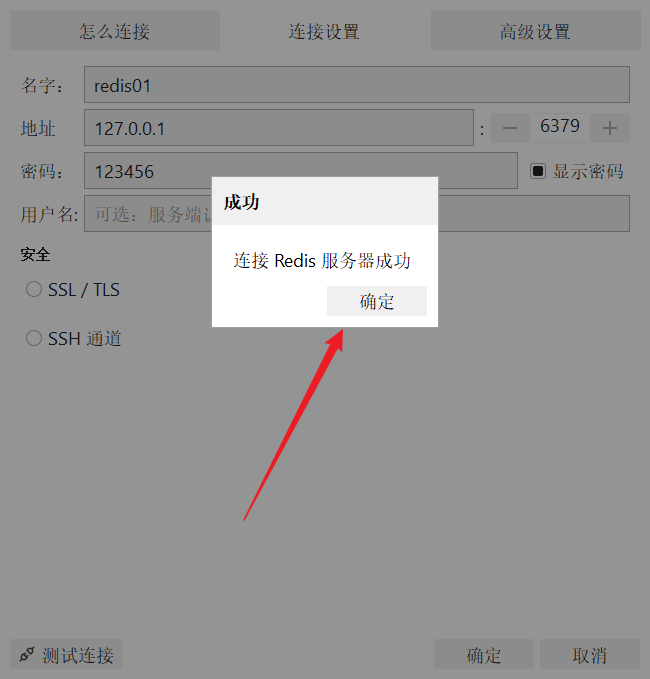
连接成功后一路确定即可
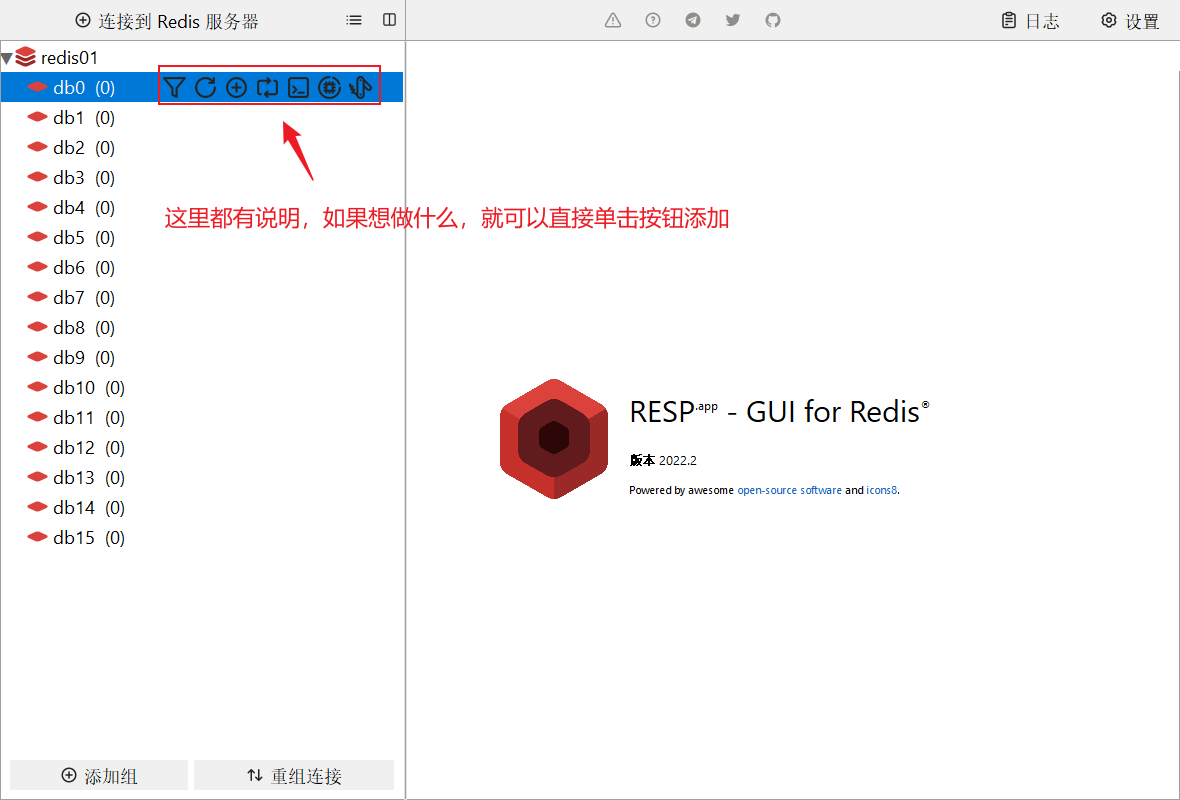
添加键后的效果如下
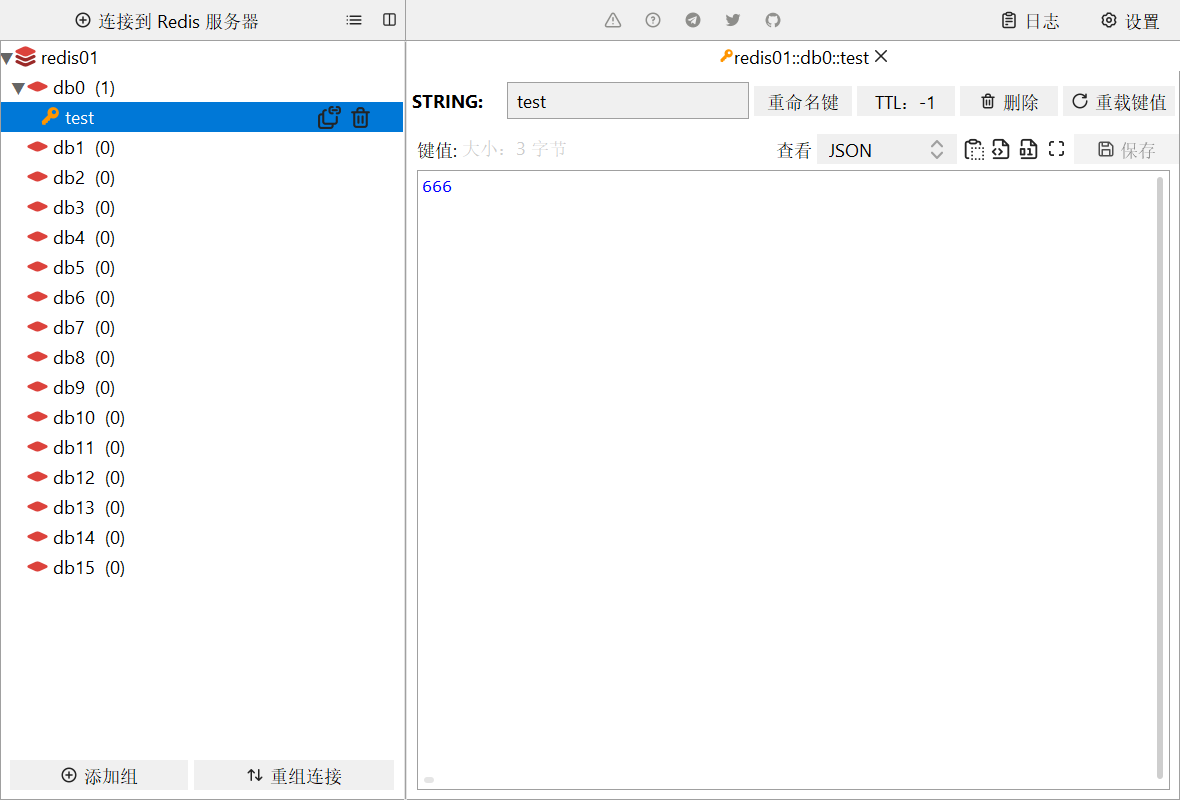
Redis常见命令
Redis数据结构介绍
Redis是一个key-value的数据库,key一般是String类型,value的类型多样

学习Redis可以多看看Redis的官方文档:https://redis.io/commands/
甚至你可以在Redis的命令行中使用help来查看帮助
bash
helpRedis的通用命令
KEYS
一般是用来查找满足条件的key
bash
KEYS pattern示例:
bash
KEYS *查询所有的key
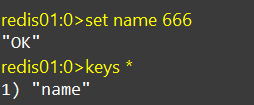
一般都是根据pattern通配符来查找专门的key
不建议在生产环境使用,因为Redis是单线程的,模糊查询很慢,如果数据量较大,一查可能会出现问题
DEL
删除一个指定的key
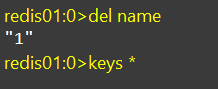
废话不多说,直接上示例
删除单个key
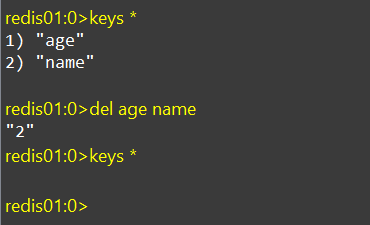
删除多个key,中间用空格隔开
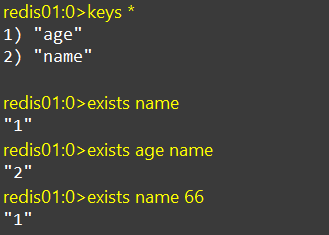
EXISTS
判断key是否存在
EXISTS后面可以传递多个key,返回的是key存在的数量
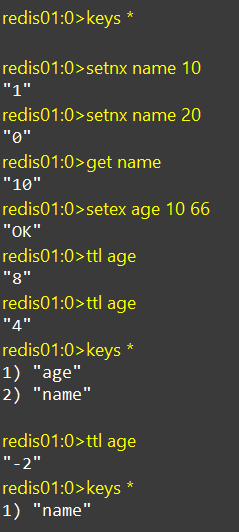
EXPIRE
为key设置有效期,到期后key会被自动删除,设置的有效期一般为秒
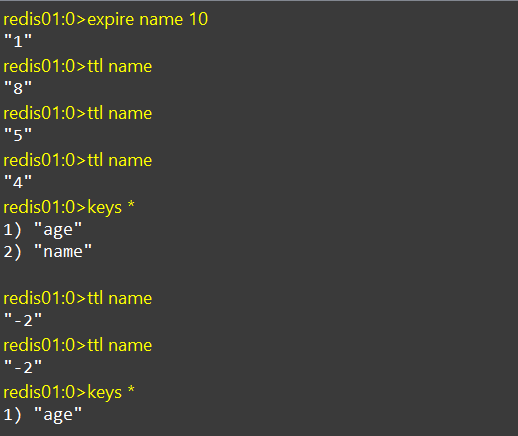
TTL
查看key的有效时间,一般和EXPIRE联用
bash
TTL key使用TTL查看一个key的默认有效时间
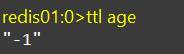
-1代表永久有效
String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
不管哪种格式,底层都是字节数组形式存储,只不过编码方式不同。字符串类型的最大空间不能超过512m
String类型的常见命令
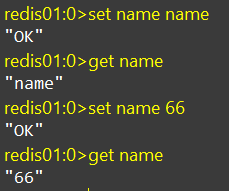
SET、GET
set:添加或者修改已经存在的一个String类型的键值对
get:根据key获取String类型的键值对
MSET、MGET
mset:批量添加多个String类型的键值对
mget:根据多个key获取多个String类型的value

INCR、INCRBY、INCRBYFLOAT
incr:让一个整型的key自增1
incrby:让一个整型的key自增,并指定步长,例如:incrby num 2,让num值自增2
incrbyfloat:让一个浮点类型的数字自增并指定步长
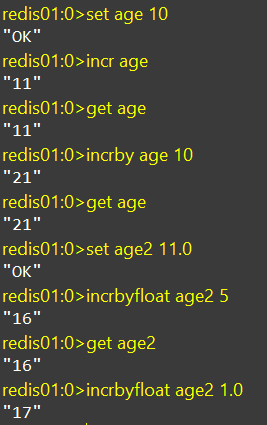
SETNX、SETEX
setnx:添加一个String类型的键值对,前提是这个key不存在,否则不执行
setex:添加一个String类型的键值对,并且指定有效期
Key的层级格式
Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
Redis的key允许有多个单词形成层级结构,多个单词之间用`:`隔开,格式如下:
txt
项目名:业务名:类型:id这个格式并非固定,也可以根据自己的需求来删除和添加词条
例如我们的项目叫eastwind,有user和product两种不同类型的数据,我们可以这样定义key
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
测试一下层级

添加以下代码后,来到redis的桌面端查看
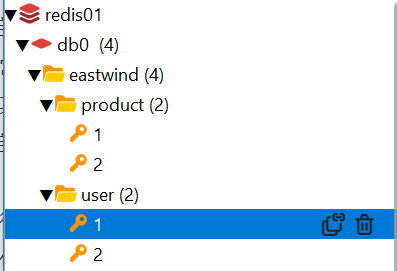
此时这里就有了层级关系
Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
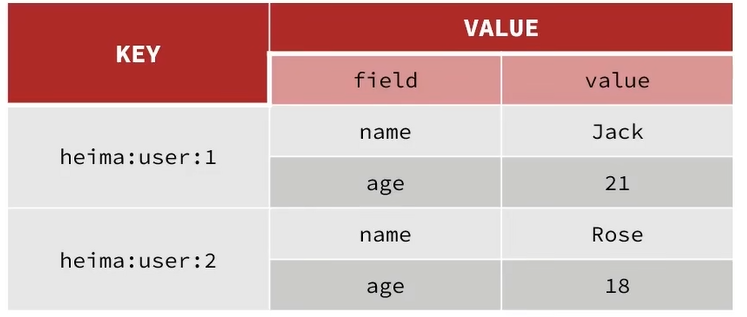
Hash类型的常见命令
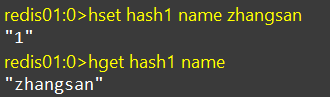
HSET、HGET
hset:添加或修改hash类型key的field的值
hset hash名 字段名 值hget:获取一个hash类型key的field的值
hget hash名 字段名
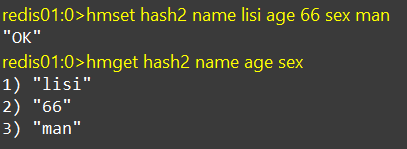
HMSET、HMGET
hmset:添加多个键值对
hmget:获取多个键值对
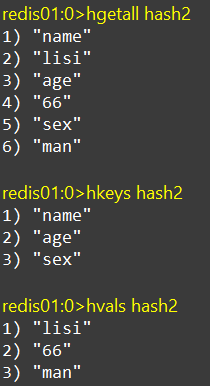
HGETALL、HKEYS、HVALS
hgetall:获取一个hash类型中的所有字段和值
hkeys:获取一个hash类型中所有的字段
hvals:获取一个hash类型中所有的值
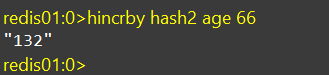
HINCRBY
hincrby:让一个hash类型的字段值自增并指定步长
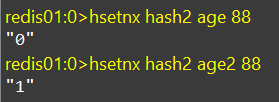
HSETNX
hsetnx:添加一个hash类型的字段值,前提是该字段不存在,否则不执行
List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
关于左侧和右侧插入的情况,举出一个例子
我们想插入值C,如果在左侧插入,那么就在A的前面,如果在右侧插入,就在B的后面
A-B
C-A-B
A-B-CList类型的常见命令
LPUSH
向列表左侧插入一个或多个元素

根据上面的例子,我们会依次插入name、123、jsda,都是左侧插入,所以插入顺序如下
jsda-123-name

LPOP
lpop:移除并返回列表左侧的第一个元素,没有则返回nil
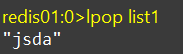
RPUSH
向列表右侧插入一个或多个元素
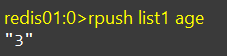
右侧插入也是同理,我们这次只插入了一个age
123-name-age

LRANGE
xxxxxxxxxx @Testvoid commonTest() { //查看所有key(keys ) Set
BLPOP、BRPOP
与LPOP和RPOP类似,唯一不同是会在没有元素时等待指定时间,而不是直接返回nil
Set
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
Set类型常见命令
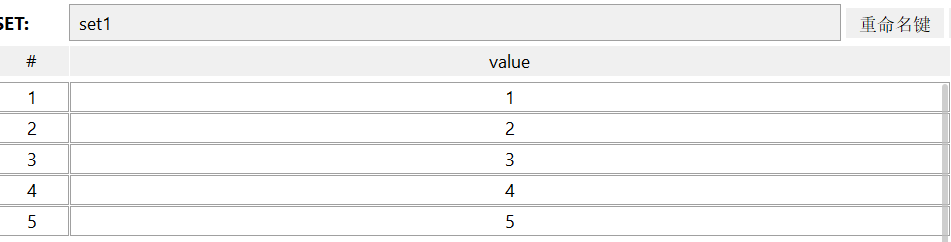
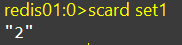
SADD、SREM、SCARD
sadd:向set中添加一个或多个元素
不会重复
srem:移除set中的指定元素
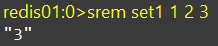

scard:返回set中元素的个数
SISMEMBER、SMEMBERS
sismember:判断一个元素是否存在于set中
smembers:获取set中的所有元素
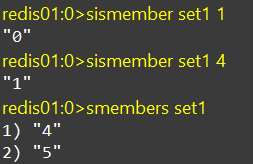
SINTER、SUNION、SDIFF
sinter:求两个集合的交集
sunion:求两个集合的并集
sdiff:求两个集合的差集(补集)
SortedSet
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令
ZADD、ZREM
zadd:添加一个或多个元素到sorted set,如果已经存在则更新其score值
zrem:删除sorted set中的一个指定元素




ZSCORE、ZRANK
zscore:获取sorted set中指定元素的score值
zrank:获取sorted set中的指定元素的排名,一般分数越高,排名越靠后
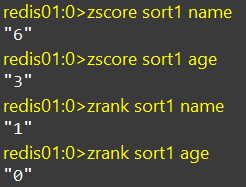
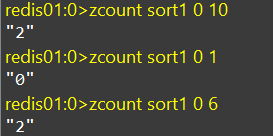
ZCARD、ZCOUNT
zcard:统计元素个数
zcount:统计score值在给定范围内的所有元素的个数
ZINCRBY
让sorted set中的指定元素自增,步长为指定的值,添加的是score

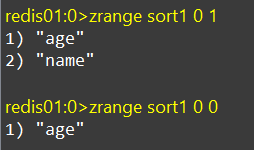
ZRANGE
按照score排序后,获取指定范围内的元素,这里的范围代指索引,也可以称为排名
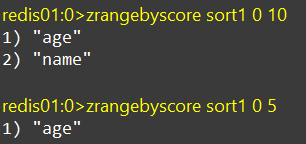
ZRANGEBYSCORE
按照score排序后,获取score范围内的元素,根据score来获取值
ZDIFF、ZINTER、ZUNION
求差集、交集、并集,跟set一致
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
Redis的Java客户端
Jedis
快速入门
新建一个maven工程
引入依赖
xml
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>在test下新建Java类
建立连接
java
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
public class JedisTest {
private Jedis jedis;
// @BeforeEach在测试类方法执行前所执行的方法
@BeforeEach
void setup(){
// 1、建立连接
jedis = new Jedis("127.0.0.1",6379);
// 2、设置密码
jedis.auth("123456");
// 3、选择库
jedis.select(0);
}
@AfterEach
void tearDown() {
// 关闭连接
if (jedis != null)
jedis.close();
}
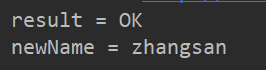
@Test
void test1(){
// 存储数据
String result = jedis.set("name", "zhangsan");
System.out.println("result = " + result);
// 获取数据
String s = jedis.get("name");
System.out.println("newName = " + s);
}
}结果如下
报错是正常的,这个不用管

接着测试一下其他的写法
Hash
java
@Test
void test2(){
jedis.hset("user:1","name","zhangsan");
jedis.hset("user:1","age","10");
jedis.hset("user:1","score","99.9");
Map<String, String> hgetAll = jedis.hgetAll("user:1");
System.out.println(hgetAll);
}

其他的也是类似的,只要知道命令就会写了
Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会造成有性能损耗,因此我们推荐Jedis连接池代替Jedis的直连方式
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static {
// 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
// 最大连接数
poolConfig.setMaxTotal(8);
// 设置最大空闲时间,预备8个池子,即使没人访问,依然有8个池子
poolConfig.setMaxIdle(8);
// 最少可以为0,即使没人用,也可以释放掉
poolConfig.setMinIdle(0);
// 设置等待时间为1秒,池子满了无法连接一秒后就报错
poolConfig.setMaxWaitMillis(1000);
// 创建连接池对象
jedisPool = new JedisPool(poolConfig,"127.0.0.1",6379,1000,"123456");
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}并修改JedisTest中的连接方法
java
// @BeforeEach在测试类方法执行前所执行的方法
@BeforeEach
void setup(){
// 1、建立连接
jedis = JedisConnectionFactory.getJedis();
// 2、设置密码
jedis.auth("123456");
// 3、选择库
jedis.select(0);
}再次测试
SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis
官网地址:https://spring.io/projects/spring-data-redis
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

快速入门
创建一个Spring Boot项目
引入依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.15</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>fun.eastwind</groupId>
<artifactId>RedisDemo2</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>RedisDemo2</name>
<description>RedisDemo2</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- common-pool依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>配置application.yaml文件
yaml
spring:
redis:
host: 127.0.0.1
port: 6379
password: 123456
lettuce:
pool:
# 最大连接数
max-active: 8
# 空闲时最大可连接数
max-idle: 8
# 空闲时最少可连接数
min-idle: 0
# 连接的最大等待时间
max-wait: 100ms自动注入RedisTemplate并测试
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisDemo2ApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","zhangsan");
String name = (String) redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}RedisTemplate的RedisSerializer(序列化器)
为什么说序列化器呢,当你执行完刚刚的测试代码后,去Redis客户端中get这个name字段

此时会发现是zhangsan,当你在Redis客户端后重新设置name,name会改变,而你在自己写的测试上运行后,再次get,依然是客户端上的值,这是怎么回事呢,我们keys *查看一下所有的key
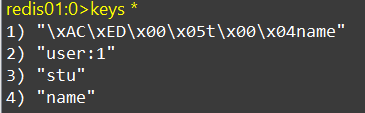
此时发现了一个很奇怪的东西,但不可否认的,这个key就是你刚刚set上去的name
RedisTemplate可以接收任意Object作为值写入Redis
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的
`"\xAC\xED\x00\x05t\x00\x04name"`
缺点:
我们可以自定义RedisTemplate的序列化方式
引入JackSon依赖
xml
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>编写配置类
java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisTemplateSerializer {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
// 创建RedisTemplate对象
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 设置连接工厂
redisTemplate.setConnectionFactory(connectionFactory);
// 设置JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key的序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置value的序列化
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
// 返回
return redisTemplate;
}
}测试类
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisDemo2ApplicationTests {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","lisi");
String name = (String) redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}

此时就成功了,如果你存入对象的话,会自动转为json对象并存入
StringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
因为存入和读取时的序列化及反序列化都是我们自己实现的,SpringDataRedis就不会将class信息写入Redis了
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
普通属性(非对象)
java
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class RedisDemo2ApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void contextLoads() {
stringRedisTemplate.opsForValue().set("name","lisi");
String name = (String) stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}对象(手动序列化)
java
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class RedisDemo2ApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void contextLoads() throws JsonProcessingException {
User zhangsan = new User("zhangsan", 66);
// 手动序列化对象(将对象写成json)
String value = mapper.writeValueAsString(zhangsan);
// 写入数据
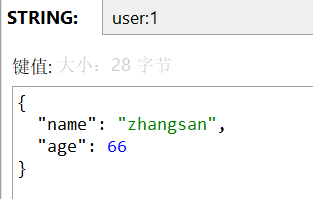
stringRedisTemplate.opsForValue().set("user:1",value);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:1");
// 手动反序列化对象
User user = mapper.readValue(jsonUser, User.class);
System.out.println("user = " + user);
}
}优点:大大减少了字节码文件的空间
关于其他的类型,其实都是类似的,这里也不再赘述了