缓存优化
使用Git管理代码
先让IDEA绑定`Github`,在vcs下选择创建一个git仓库,并选择需要被Git管理的目录,选择确认
再右击整个项目,菜单栏有个Git,依次点击命令即可
记得选中整个文件夹,不然推送可能不一定完整,commit后会出现以下情况,展示页面跟IDEA的版本有关,不过整体内容大差不差
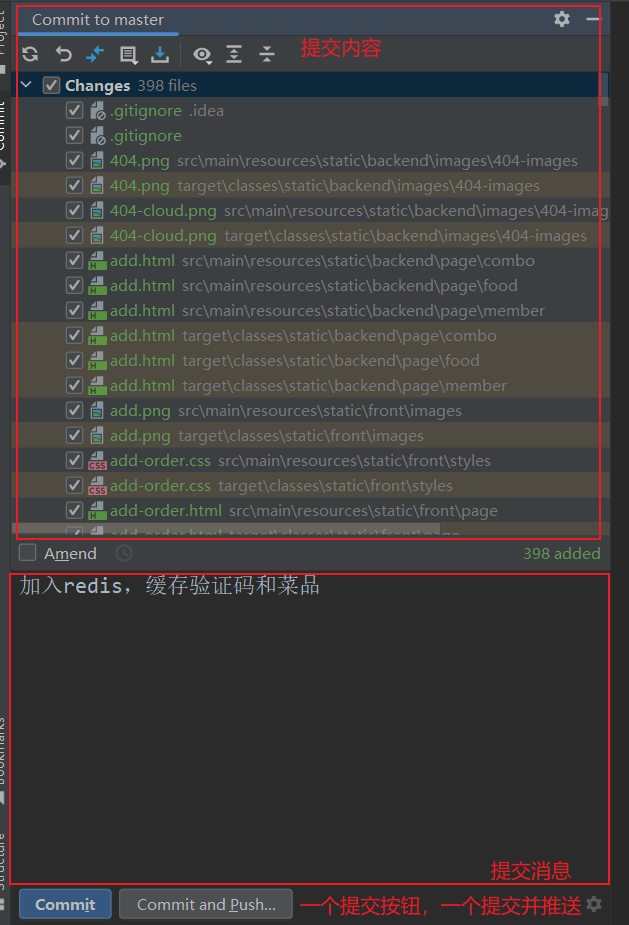
这里我们选择连Commit and Push提交带推送,这样比较快捷,但是我们还没有设置自己的远程仓库,需要去Github上复制一下自己的仓库地址来进行上传
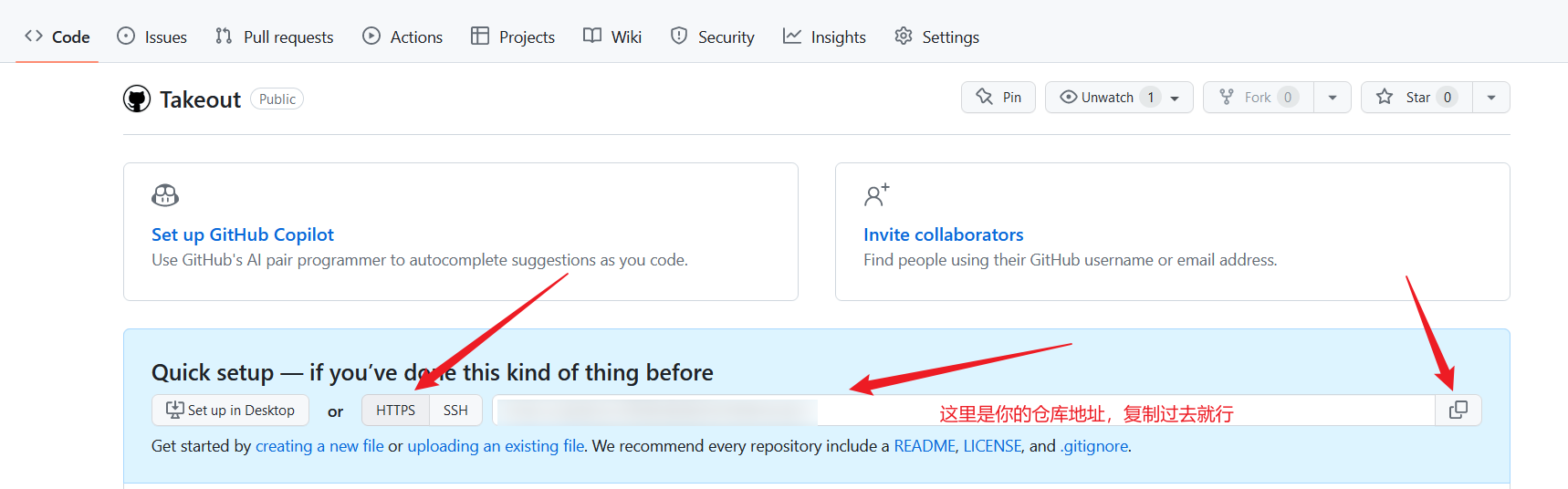
Commit and Push后出现以下页面
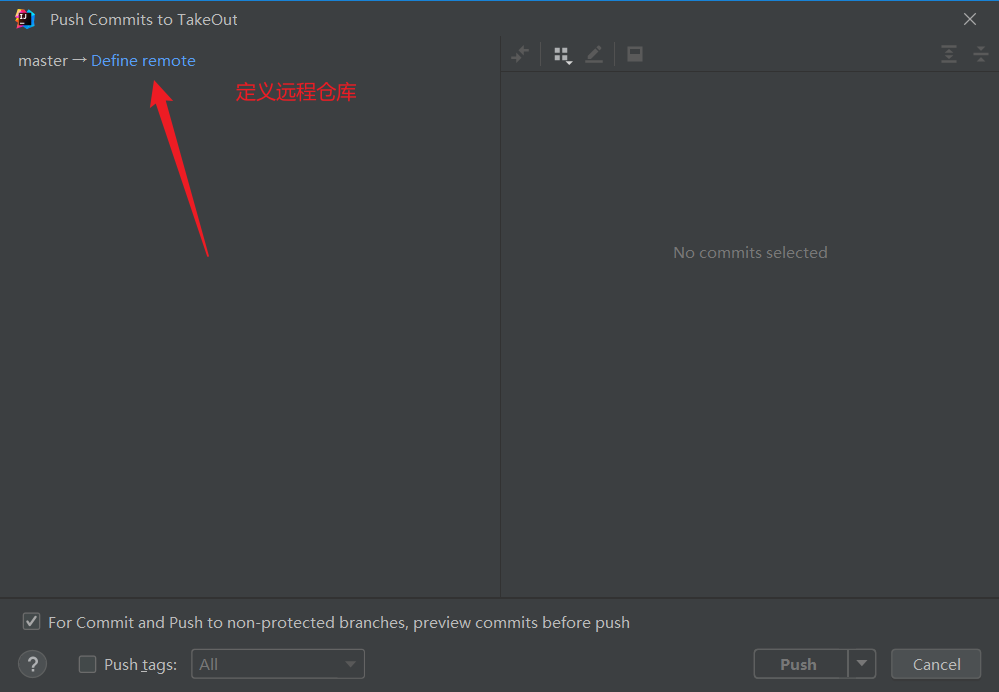
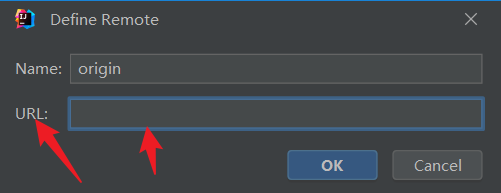
在这里定义远程仓库,把刚刚复制的仓库地址粘贴上去
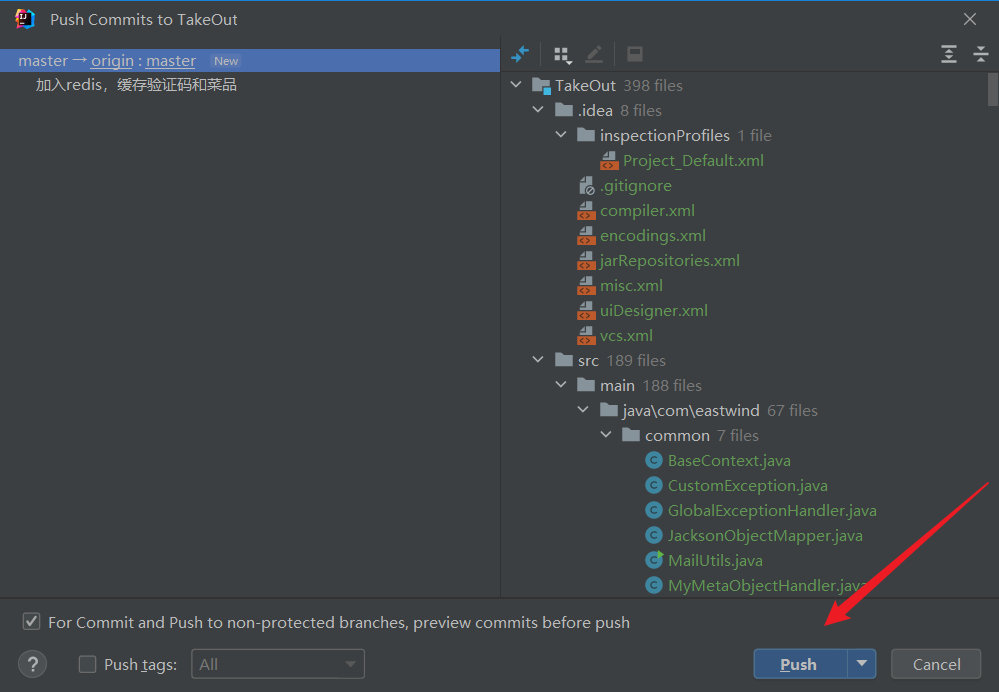
点击push推送过去,可能会让你登录一下Github进行授权啥的,这里登录就行了,然后等待推送完成,去Github上面查看一下,有就成功了
这时候我们再创建一个新的分支,把内容跟master分支分隔开
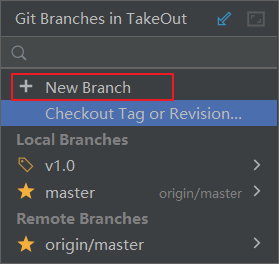
这里我创建了一个v1.0的分支
然后,我们把内容推送到v1.0这个分支上去
现在的内容没有变化,是因为还没有修改代码的内容,后期在v1.0上开发,内容就不一样了
在v1.0上开发完成后,还可以将内容合并回master分支上,非常方便和快捷,即使写错了也不会修改原master上的代码
环境搭建
问题说明
问题说明:
导入SpringDataRedis的maven坐标
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>redis配置文件
yaml
redis:
host: localhost #这里换成localhost或者你自己的linux上装的redis
password: 123456
port: 6379
database: 0配置序列化器
java
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
// 设置键的序列化器统一
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
// 设置值的序列化器统一
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}最后将修改完的数据提交并推送到那个新的v1.0的分支上去即可
缓存手机验证码
实现思路
先想一下之前做的邮件验证码是存储在哪的
存储在Session域中,现在学习了Redis,就可以缓存在Redis中
操作步骤如下:
1. 在服务端UserController中注入RedisTemplate对象,用于操作Redis;
2. 在服务端UserController中的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟,因为一般的手机短信有效期也为5分钟
3. 在服务端UserController中的login方法中,从Redis中获取缓存的代码,如果登录成功则删除Redis的验证码
代码改造
在UserController中注入RedisTemplate对象,用于操作Redis
java
@Autowired
private RedisTemplate redisTemplate;在服务端UserController中的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟
修改前后比较
diff
@PostMapping("/sendMsg")
public Result<String> sendMsg(@RequestBody User user, HttpSession session) throws MessagingException {
String phone = user.getPhone();
if (!phone.isEmpty()) {
//随机生成一个验证码
String code = MailUtils.achieveCode();
log.info(code);
//这里的phone其实就是邮箱,code是我们生成的验证码
MailUtils.sendTestMail(phone, code);
- //验证码存session,方便后面拿出来比对phone
- session.setAttribute(phone, code);
+ // 验证码缓存到Redis中,设置存活时间5分钟
+ redisTemplate.opsForValue().set("code",code,5, TimeUnit.MINUTES);
return Result.success("验证码发送成功");
}
return Result.error("验证码发送失败");
}修改后的代码
java
@PostMapping("/sendMsg")
public Result<String> sendMsg(@RequestBody User user, HttpSession session) throws MessagingException {
String phone = user.getPhone();
if (!phone.isEmpty()) {
//随机生成一个验证码
String code = MailUtils.achieveCode();
log.info(code);
//这里的phone其实就是邮箱,code是我们生成的验证码
MailUtils.sendTestMail(phone, code);
// 存储到Redis中并设置5分钟的存活时间
redisTemplate.opsForValue().set("code",code,5, TimeUnit.MINUTES);
return Result.success("验证码发送成功");
}
return Result.error("验证码发送失败");
}在服务端UserController中的login方法中,从Redis中获取缓存的代码,如果登录成功则删除Redis的验证码
修改前后比较
diff
@PostMapping("/login")
public Result<User> login(@RequestBody Map map, HttpSession session) {
// 获取邮箱
String phone = map.get("phone").toString();
// 获得验证码,需要和系统内部的验证码进行比对
String code = map.get("code").toString();
- // 从session中获得验证码,session中的验证码之前在发送时,已经让服务器获得了
- String codeInSession = session.getAttribute(phone).toString();
+ // 把刚刚存入Redis的code拿出来
+ Object codeInRedis = redisTemplate.opsForValue().get("code");
- if (code != null && code.equals(codeInSession)) {
// 用redis中的code进行比较
+ if (code != null && code.equals(codeInRedis)) {
// 如果输入正确,验证用户是否存在
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getPhone, phone);
User user = userService.getOne(queryWrapper);
if (user == null) {
// 如果user为空,就创建一个新的user对象
user = new User();
user.setPhone(phone);
userService.save(user);
- user.setName("用户" + codeInSession);
+ user.setName("用户" + codeInRedis);
}
// 存个session,表示登录状态
session.setAttribute("user", user.getId());
// 并作为结果返回
+ // 如果登录成功,则删除Redis中的验证码
+ redisTemplate.delete("code");
return Result.success(user);
}
return Result.error("登录失败");
}修改后的代码
java
@PostMapping("/login")
public Result<User> login(@RequestBody Map map, HttpSession session) {
// 获取邮箱
String phone = map.get("phone").toString();
// 获得验证码,需要和系统内部的验证码进行比对
String code = map.get("code").toString();
// 把刚刚存入Redis的code拿出来
Object codeInRedis = redisTemplate.opsForValue().get("code");
// 判断从Redis中获取的code是否相同
if (code != null && code.equals(codeInRedis)) {
// 如果输入正确,验证用户是否存在
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getPhone, phone);
User user = userService.getOne(queryWrapper);
if (user == null) {
// 如果user为空,就创建一个新的user对象
user = new User();
user.setPhone(phone);
userService.save(user);
user.setName("用户" + codeInRedis);
}
// 存个session,表示登录状态
session.setAttribute("user", user.getId());
// 并作为结果返回
// 如果登录成功,则删除Redis中的验证码
redisTemplate.delete("code");
return Result.success(user);
}
return Result.error("登录失败");
}功能测试
在测试时,发现一个报错:ERR Client sent AUTH, but no password is set,说是密码没有设置,原因是我们是通过redis-server.exe启动的,而双击启动默认是去找redis.conf的配置文件,然后没找到,所以也就报了之前的ERR Client sent AUTH, but no password is set错误。
解决办法:
方案1:
在redis安装目录下找到redis.windows.conf文件
找到这一行: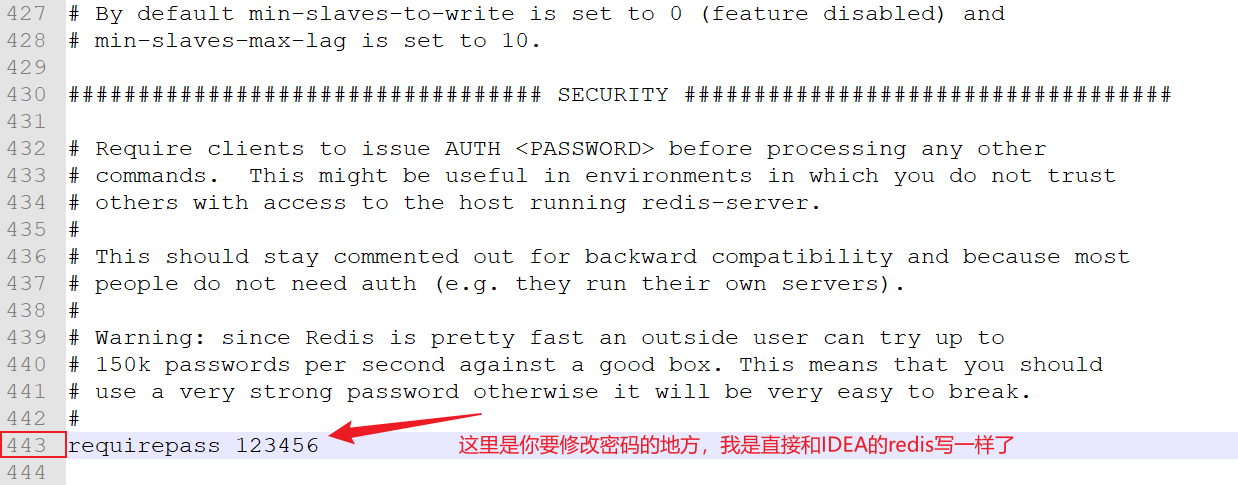
然后在redis目录下cmd运行命令:`redis-server.exe redis.windows.conf`
方案2:
其实就没设置密码,你直接把IDEA里的密码删了就行,无需密码可以直接访问
其实是类似于之前在Linux中的vim文件里的配置
这里我采用的是方案2,方案1我试了几次,感觉比较麻烦,所以我采用了方案2
配好之后我们再次测试
打开redis的服务器和客户端
获取邮箱验证码后,在redis中进行查看

这里发现,redis中已经缓存了我们的数据了
此时我们进行登录
此时就登录成功了,我们再去看看验证码有没有被删除

缓存菜品数据
实现思路
1. 修改DishController中的list方法,先从Redis中获取分类对应的菜品数据,如果有,则直接返回;如果无,则查询数据库,并将查询到的菜品数据存入Redis缓存中
2. 修改DishController的save、update和delete方法,加入清理缓存的逻辑,避免产生脏数据,也就是说我们修改/更新/删除了菜品,但是缓存没有被清理,数据还是之前的,所以展示的还是之前的,我们需要清理缓存,让它重新加载数据(其实就是我们实际已经在后台修改/更新/删除了某些菜品,但由于缓存数据未被清理,未重新查询数据库,用户看到的还是我们修改之前的数据)
代码改造
在DishController中需要注入`RedisTemplate`来使用Redis
java
@Autowired
private RedisTemplate redisTemplate;修改后的代码如下
梳理一下思路,设立一个key用于区分不同的缓存内容,比如1号菜品里有什么菜,二号菜品有什么菜,这些缓存的key都是不同的,不能放在一个里面,通过key来进行区分,然后我们先从redis中获取对应的key,来进行判断,如果key存在,说明该缓存存在,直接返回缓存即可,否则,进行数据的查询,查询完成后,再使用redis进行数据的保存,最后返回数据
java
@GetMapping("/list")
// 先将返回值类型改为List<DishDto>
public Result<List<DishDto>> list(Dish dish){
// 将dishDtoList作为内容缓存到Redis中
List<DishDto> dishDtoList = null;
// key是用于区分不同的缓存内容
String key = "dish_" + dish.getCategoryId() + "_" + dish.getStatus();
// 先从redis中获取缓存数据(获取的缓存数据应该是应该为dishDtoList)
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
// 如果存在,返回数据,无需查询
if (dishDtoList != null){
// 直接将查询到的缓存数据返回
return Result.success(dishDtoList);
}
// 如果不存在,就需要进行查询,并使用redis加以缓存
// 以下代码都是进行数据查询
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
// 得到该菜品项对应的菜品
queryWrapper.eq(dish.getCategoryId() != null,Dish::getCategoryId,dish.getCategoryId());
// 添加条件,查询状态为1(起售状态)的菜品
queryWrapper.eq(Dish::getStatus,1);
//添加排序条件(先按照sort来排序,如果sort相同,再按照更新时间来排序)
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
dishDtoList = list.stream().map((item) -> {
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(item,dishDto);
// 分类id
Long categoryId = item.getCategoryId();
// 根据Id查询分类对象
Category category = categoryService.getById(categoryId);
if (category != null){
// 如果分类对象查询到了,说明该菜品有分类
String categoryName = category.getName();
// 就让菜品设置一下这个分类对象名字
dishDto.setCategoryName(categoryName);
}
// 得到菜品的id
Long itemId = item.getId();
LambdaQueryWrapper<DishFlavor> wrapper = new LambdaQueryWrapper<>();
// 查找与当前菜品id相同的口味信息
wrapper.eq(DishFlavor::getDishId,itemId);
List<DishFlavor> flavors = dishFlavorService.list(wrapper);
// 设置菜品口味
dishDto.setFlavors(flavors);
return dishDto;
}).collect(Collectors.toList());
// 将数据缓存到redis中,避免二次查询(并设置缓存时间为60分钟)
redisTemplate.opsForValue().set(key,dishDtoList,60, TimeUnit.MINUTES);
return Result.success(dishDtoList);
}为save和update方法加入清理缓存的逻辑
java
@PostMapping
public Result<String> save(@RequestBody DishDto dishDto) {
dishService.saveWithFlavor(dishDto);
String key = "dish_" + dishDto.getCategoryId() + "_1";
// 删除之前的key,也就是清除缓存,之前的内容就不存在了,会去数据库中重新查找
redisTemplate.delete(key);
return Result.success("新增菜品成功");
}java
@PutMapping
public Result<String> update(@RequestBody DishDto dishDto) {
dishService.updateWithFlavor(dishDto);
String key = "dish_" + dishDto.getCategoryId() + "_1";
// 删除之前的key,也就是清除缓存,之前的内容就不存在了,会去数据库中重新查找
redisTemplate.delete(key);
return Result.success("更新菜品成功");
}这里我还没有写这个停售起售的功能,所以就没有进行更改,后期项目做完了再回头来补
注意:这里并不需要我们对删除操作也进行缓存清理,因为删除操作执行之前,必须先将菜品状态修改为`停售`,而停售状态也会帮我们清理缓存,同时也看不到菜品,随后将菜品删除,仍然看不到菜品,故删除操作不需要进行缓存清理
功能测试
在进行测试前,我们需要做一件事,就是修改RedisConfig类中之前写的值的序列化器统一,之前把他们统一成String了,所以就会只能返回String,我们去注释掉里面的代码
java
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
// 设置键的序列化器统一
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
// 设置值的序列化器统一
// redisTemplate.setValueSerializer(new StringRedisSerializer());
// redisTemplate.setHashValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}然后启动测试
此时,内容就都展现出来了
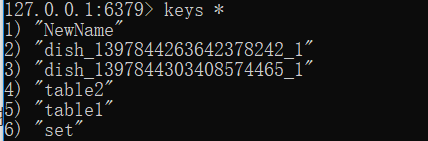
并且,我们也能在redis中查询得到菜品的数据,其他内容我就不测试了,有兴趣可以自己测一下
最后,我们将这次写的代码push到github上
Spring Cache
4.1Spring Cache介绍
SpringCache使用方式
在springboot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用`@EnableCaching`开启缓存支持即可
如果只是使用SpringCache的基础功能,只需要导入spring-boot-starter-web这个包就可以了
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>compile</scope>
</dependency>使用Redis作为缓存技术,需要导入`Spring data Redis`的maven坐标即可
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>随后配置application.yml
yml
spring:
redis:
host: localhost #这里换成localhost或者你自己的linux上装的redis
# 这里我没有密码的原因是之前在缓存菜品数据的时候告诉我需要密码,我感觉有点麻烦就把密码去掉了
# 有需要可以自己设置一下
# password: 123456
port: 6379
database: 0
cache:
redis:
time-to-live: 3600000 #设置缓存存活时间为一小时,如果不设置,则一直存活Spring Cache常用注解
@Cacheable
`@Cacheable`的作用主要针对在方法执行前spring先查看缓存中是否有数据。如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中,其主要参数说明如下
@CachePut
`@CachePut`的作用主要针对方法配置,能够根据方法的请求参数对其结果进行缓存,将方法的返回值放入缓存
这边的key可以通过里面的参数名.属性的形式来获取,使用#参数名.属性就可以将数据放入缓存中
当整个方法执行完后,通过返回的值来给key赋上值,缓存的值是被返回的整个对象
例如:
java
@CachePut(value = {"userCache","userCacher2"},key = "#user.id")
@PostMapping
public User save(User user){
userService.save(user);
// user是参数名,通过user.id就可以得到用户的id
// 当整个方法执行完后,就会将key赋上值
// 缓存的值是返回的整个对象,而key是自己设定的缓存key
return user;
}@CacheEvict
`@CacheEvict`的作用是清除缓存
`@CacheEvict`可以清除某个缓存名称下的key缓存数据
例如:
java
// 如果key为#p1,#p2这种,代表有多参数,根据p后面的数字来决定的
@CacheEvict(value = "userCache",key = "#p0") // #p0代表第一次参数id
//@CacheEvict(value = "userCache",key = "#root.args[0]") 这个与#p1,#p2方法类似,也是参数列表
//@CacheEvict(value = "userCache",key = "#id") 通过名称获取
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}缓存套餐数据
在做套餐之前,我们可以先用注解的方式去缓存菜品数据
先在main下开启缓存功能
java
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.web.servlet.ServletComponentScan;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Slf4j
@SpringBootApplication
@ServletComponentScan
@EnableTransactionManagement
@EnableCaching
public class TakeOutApplication {
public static void main(String[] args) {
SpringApplication.run(TakeOutApplication.class, args);
log.info("项目启动成功...");
}
}然后来到DishController的list方法下进行修改
java
@GetMapping("/list")
@Cacheable(value="DishCache",key = "#dish.getCategoryId() + '_' + #dish.getStatus()",unless = "#result == null")
// 先将返回值类型改为List<DishDto>
public Result<List<DishDto>> list(Dish dish){
// 将dishDtoList作为内容缓存到Redis中
List<DishDto> dishDtoList = null;
// 如果不存在,就需要进行查询,并使用redis加以缓存
// 以下代码都是进行数据查询
LambdaQueryWrapper<Dish> queryWrapper = new LambdaQueryWrapper<>();
// 得到该菜品项对应的菜品
queryWrapper.eq(dish.getCategoryId() != null,Dish::getCategoryId,dish.getCategoryId());
// 添加条件,查询状态为1(起售状态)的菜品
queryWrapper.eq(Dish::getStatus,1);
//添加排序条件(先按照sort来排序,如果sort相同,再按照更新时间来排序)
queryWrapper.orderByAsc(Dish::getSort).orderByDesc(Dish::getUpdateTime);
List<Dish> list = dishService.list(queryWrapper);
dishDtoList = list.stream().map((item) -> {
DishDto dishDto = new DishDto();
BeanUtils.copyProperties(item,dishDto);
// 分类id
Long categoryId = item.getCategoryId();
// 根据Id查询分类对象
Category category = categoryService.getById(categoryId);
if (category != null){
// 如果分类对象查询到了,说明该菜品有分类
String categoryName = category.getName();
// 就让菜品设置一下这个分类对象名字
dishDto.setCategoryName(categoryName);
}
// 得到菜品的id
Long itemId = item.getId();
LambdaQueryWrapper<DishFlavor> wrapper = new LambdaQueryWrapper<>();
// 查找与当前菜品id相同的口味信息
wrapper.eq(DishFlavor::getDishId,itemId);
List<DishFlavor> flavors = dishFlavorService.list(wrapper);
// 设置菜品口味
dishDto.setFlavors(flavors);
return dishDto;
}).collect(Collectors.toList());
return Result.success(dishDtoList);
}在做缓存的时候报了一个错误DefaultSerializer requires a Serializable payload but received an object of type
解决方法:
为Result对象实现一个Serializable接口即可,因为Spring 会将对象先序列化再存入 Redis,所以需要实现这个接口
java
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.HashMap;
import java.util.Map;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Result<T> implements Serializable {
private Integer code; // 编码:1成功。0和其他数字失败
private String msg; // 错误信息
private T data; // 数据
private Map map = new HashMap(); // 动态数据
public static <T> Result<T> success(T data) {
Result<T> r = new Result<>();
r.code = 1; //成功状态码
r.data = data;
return r;
}
public static <T> Result<T> error(String errMsg) {
Result<T> r = new Result<>();
r.msg = errMsg; //设置错误信息
r.code = 0; //默认失败状态码,后期我们可以根据自己的需求来设置其他状态码
return r;
}
public Result<T> add(String msg, String value) {
this.map.put(msg, value);
return this;
}
}记得删除缓存,在方法中删除缓存使用`@CacheEvict`
save:
java
@PostMapping
@CacheEvict(value = "DishCache",key = "#dishDto.getCategoryId() + '_1'")
public Result<String> save(@RequestBody DishDto dishDto) {
dishService.saveWithFlavor(dishDto);
String key = "dish_" + dishDto.getCategoryId() + "_1";
// 删除之前的key,也就是清除缓存,之前的内容就不存在了,会去数据库中重新查找
redisTemplate.delete(key);
return Result.success("新增菜品成功");
}update:
java
@PutMapping
@CacheEvict(value = "DishCache",key = "#dishDto.getCategoryId() + '_1'")
public Result<String> update(@RequestBody DishDto dishDto) {
dishService.updateWithFlavor(dishDto);
return Result.success("更新菜品成功");
}至于为什么不给delete清缓存,在3.3功能测试有讲
这里我们的菜品就全部重新用注解重写了
再来写套餐的,写法是类似的,这里就不做说明了,直接给上代码
java
@GetMapping("/list")
@Cacheable(value = "SetmealCache",key = "#setmeal.categoryId + '_' + #setmeal.status",unless = "#result == null ")
public Result<List<SetmealDto>> list(Setmeal setmeal){
LambdaQueryWrapper<Setmeal> queryWrapper = new LambdaQueryWrapper<>();
// 得到该套餐项对应的菜品
queryWrapper.eq(setmeal.getCategoryId() != null,Setmeal::getCategoryId,setmeal.getCategoryId());
// 添加条件,查询状态为1(起售状态)的菜品
queryWrapper.eq(Setmeal::getStatus,1);
//添加排序条件(按照更新时间来排序)
queryWrapper.orderByDesc(Setmeal::getUpdateTime);
List<Setmeal> list = setMealService.list(queryWrapper);
List<SetmealDto> setmealDtoList = list.stream().map((item) -> {
SetmealDto setmealDto = new SetmealDto();
BeanUtils.copyProperties(item,setmealDto);
// 分类id
Long categoryId = item.getCategoryId();
// 根据Id查询分类对象
Category category = categoryService.getById(categoryId);
if (category != null){
// 如果分类对象查询到了,说明该套餐有分类
String categoryName = category.getName();
// 就让套餐设置一下这个分类对象名字
setmealDto.setCategoryName(categoryName);
}
// 得到套餐的id
Long itemId = item.getId();
LambdaQueryWrapper<SetmealDish> wrapper = new LambdaQueryWrapper<>();
// 查找与当前套餐id相同的口味信息
wrapper.eq(SetmealDish::getDishId,itemId);
List<SetmealDish> flavors = setmealDishService.list(wrapper);
// 设置菜品口味
setmealDto.setSetmealDishes(flavors);
return setmealDto;
}).collect(Collectors.toList());
return Result.success(setmealDtoList);
}java
@PostMapping
@CacheEvict(value = "SetmealCache",,key = "#setmealDto.categoryId + '_' + '_1'")
public Result<String> save(@RequestBody SetmealDto setmealDto) {
log.info("套餐信息:{}", setmealDto);
setMealService.saveWithDish(setmealDto);
return Result.success("套餐添加成功");
}update方法也没写,哎,后期学完补上
将代码push到仓库里
读写分离
问题分析
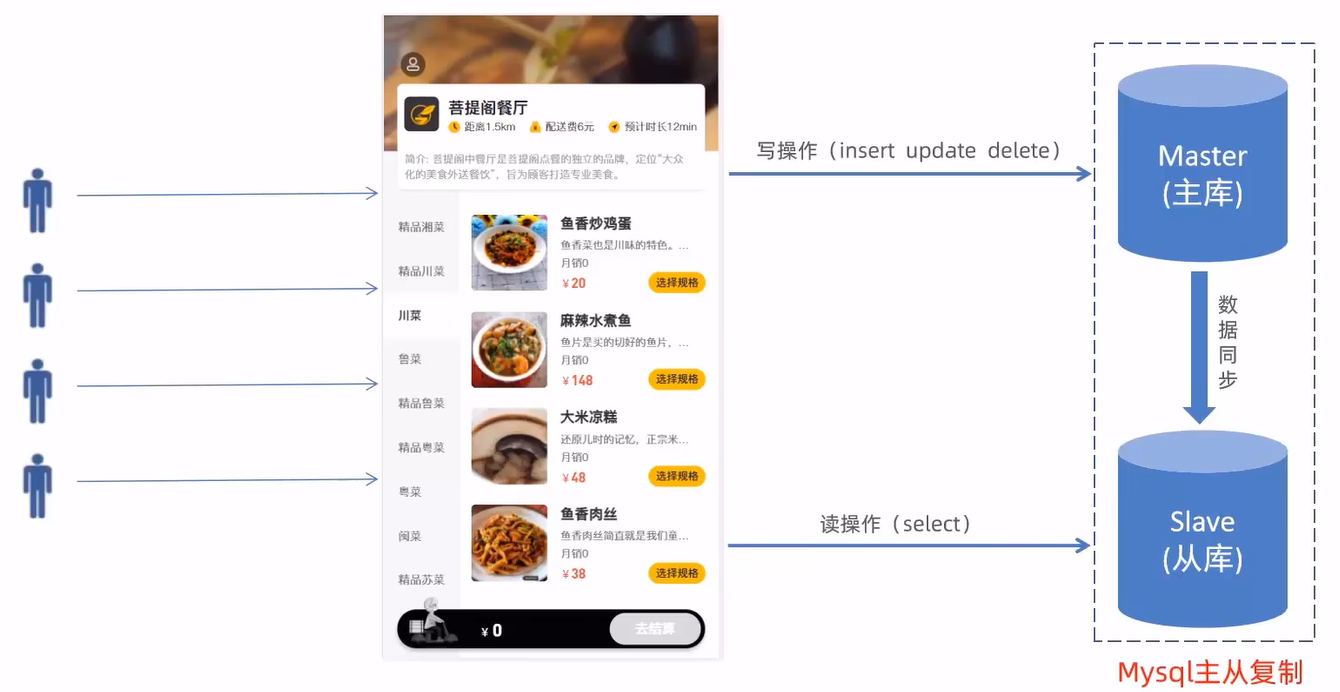
MySql主从复制
介绍
1. `maste`r将改变记录到二进制日志(`binary log`)
2. `slave`将`master`的`binary log`拷贝到它的中继日志(`relay log`)
3. `slave`重做中继日志中的事件,将改变应用到自己的数据库中
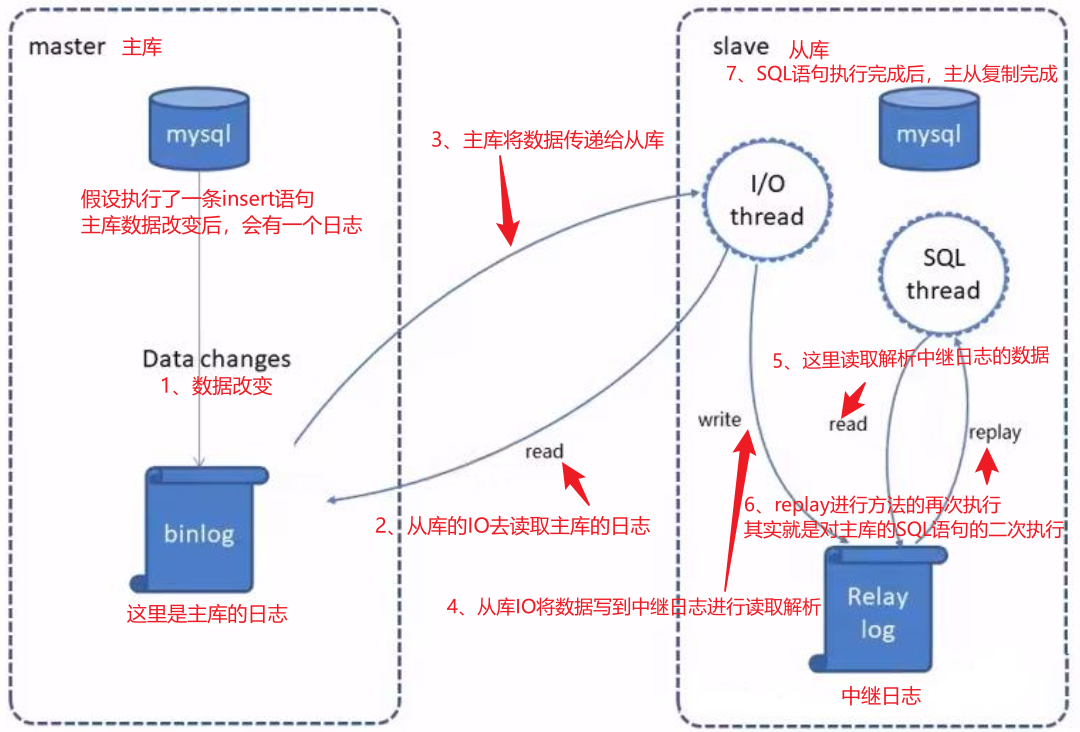
配置
前置条件
准备好两台服务器,分别安装MySQL并启动服务成功,这里准备两台虚拟机,建议使用克隆
我们先得到主库和从库的IP地址
进入系统,打开命令行,输入`ifconfig`查看IP地址
然后去mysql中连接这两个的数据库
如果在连接数据库时出现这样一个问题:

`vim /etc/my.cnf`
在[mysqld]后添加[`skip-grant-tables`(登录时跳过权限检查)

重启MySQL服务:`sudo systemctl restart mysqld`
然后输入mysql就可以进去了,在里面就可以改密码干啥了,改了密码再重新连接一下就行,或者不搞密码直接搞连接也是可以的
到数据库中连接,发现这里也可以了,我就没有设置密码,感觉设置密码比较麻烦,后面再来考虑密码的问题
数据库搞好之后,我们用Xshell来连接一下自己的服务器,一个主库,一个从库
OK,这里连接完毕,确认一下mysql服务是否开启
配置主库
修改Mysql数据库的配置文件/etc/my.cnf
bash
vim /etc/my.cnf
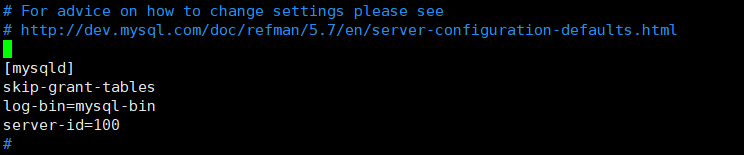
在mysqld下加入如下内容,skip-grant-tables是我们之前加上来用于跳过权限检查的
bash
log-bin=mysql-bin #[必须]启用二进制日志
server-id=100 #[必须]服务器唯一ID,值不是固定的,你只要保证唯一就行因为刚刚改了配置文件,所以我们一下重启Mysql服务
bash
systemctl restart mysqld这时候我们再登陆Mysql数据库,执行下面的SQL
sql
grant replication slave on *.* to 'eastwind'@'%' identified by '1234';在执行SQL的时候报了个异常:`The MySQL server is running with the --[skip-grant-tables] option so it cannot execute this statement`
解决方法:
先刷新一下权限表,把在所有数据库的所有表的所有权限赋值给位于所有IP地址的root用户。
sql
flush privileges;

再执行就没问题了
注:上面SQL的作用是创建一个用户eastwind,密码为1234,并且给eastwind用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
接着登录Mysql数据库,执行下面的SQL,记录下结果File和Position的值
sql
show master statussql
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 612 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)注:上面的SQL的作用是查看Master的状态,执行完该SQL后不要再执行任何操作,因为我们在执行其他任何操作时,里面的日志会变化,所以不要执行其他任何操作
配置从库
修改配置文件
跟配置从表差不多,也是在文件里面加入一点内容
bash
vim /etc/my.cnfbash
server-id=101 #[必须]服务器唯一ID
接着重启mysql服务
bash
systemctl restart mysqld登陆Mysql数据库,执行下面的SQL
sql
change master to master_host='192.168.10.135',master_user='eastwind',master_password='1234',master_log_file='mysql-bin.000001',master_log_pos=612;简单解释一下这里的配置,master_host对应主库的ip地址,master_user对应主库的用户名,master_password对应主库的密码,master_log_file对应之前主库查出来的File,master_log_pos对应对应之前主库查出来的Position,根据自己的情况修改
然后执行这条SQL
bash
start slave;最后执行一条SQL查看一下slave的状态
sql
show slave status\G;本来是`show slave status`但是显示的不太美观,所以加上\G格式化输出
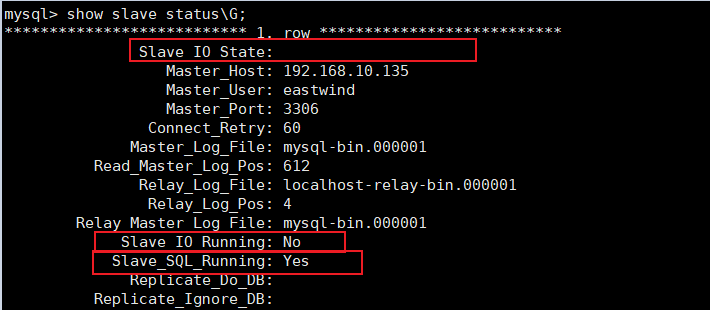
这两个是必须是yes的,并且`Slave IO State` 什么也没有,我们发现这里其中一个是no,在翻看了文档后发现是克隆机的问题,我们需要修改克隆机的uuid,现在我们修改一下uuid
sql
mysql> select uuid();
+--------------------------------------+
| uuid() |
+--------------------------------------+
| a499587b-3525-11ee-b696-000c29daa809 |
+--------------------------------------+查询克隆机的uuid,并记住它
接着查看配置文件目录
sql
mysql> show variables like "datadir";
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+编辑配置文件目录,修改uuid为刚刚我们生成的uuid
bash
vi /var/lib/mysql/auto.cnf重启服务
bash
systemctl restart mysqld再次进入mysql查看slave的状态
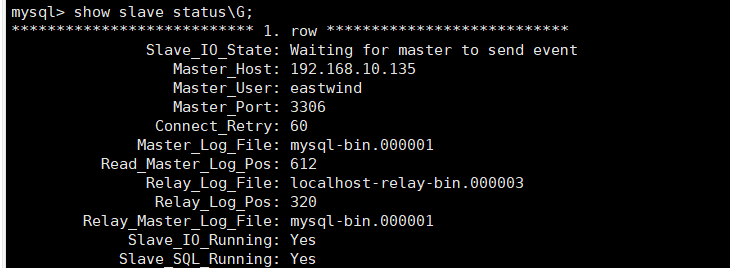
此时发现这两个都是Yes了,并且`Slave IO State`也有了对应的内容,说明我们的配置完成了
测试
在主库中新建数据库,刷新一下从库
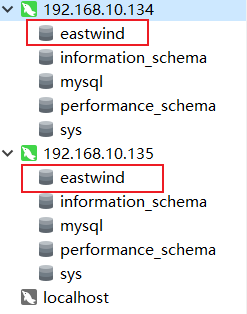
继续在主库中进行测试,新建一张表,对表进行一下增删改操作,看看从库中是否有变化,如果有变化说明配置的没有问题,这里其他的测试我就不展示了,挺简单的
读写分离案例
背景
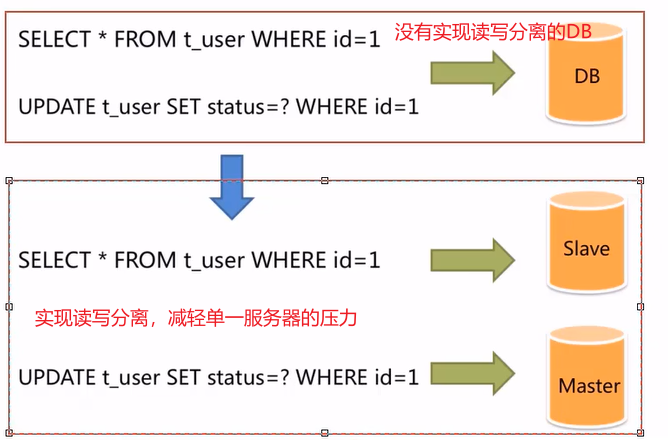
面对日益增加的系统访问量,数据库的吞吐量面临着巨大的瓶颈。对于同一时刻有`大量并发读操作`和`较少的写操作`类型的应用系统来说,将数据库拆分为`主库`和`从库`,`主库`主要负责处理事务性的`增删改操作`,从库`主要负责查询操作`,这样就能有效避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善
Sharding-JDBC介绍
1. 导入对应的maven坐标
xml
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2. 在配置文件中配置读写分离规则,并配置允许bean定义覆盖配置项
yaml
spring:
shardingsphere:
datasource:
names:
# 这里的master和slave并不是写死的,但是需要跟下面的master和slave对应
# 定义了两个数据源,名叫master和slave
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
# 主库ip及连接的数据库名
url: jdbc:mysql://192.168.10.135:3306/reggie?serverTimezone=UTC&useSSL=false
username: root
# 我的数据库没有密码,所以这里注释了,有需要可以自己调整
# password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
# 从库ip及连接的数据库名
url: jdbc:mysql://192.168.10.134:3306/reggie?serverTimezone=UTC&useSSL=false
username: root
# password: root
masterslave:
# 读写分离配置
# 负载均衡:配置的是从库的负载均衡策略(轮询策略)
# 轮询:从库可以有多个,假设有3个从库,第一次走sql查询就是走1号库,第二次走2号,这样以此类 推,直到走完之后再次重复一遍,说白了就是按顺序来
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 指定主库数据源名称
master-data-source-name: master
# 指定从库数据源名称列表,多个从库用逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false,就是在控制台可以输出sql
# 配置允许bean定义覆盖配置项
main:
allow-bean-definition-overriding: true
项目实现读写分离
之前已经搭建好了主从复制的数据库,现在到主库去搭建项目的数据库
相应的,从库里面也会创建,检查一下就行
然后运行一下之前的sql文件代码
记得把这个下面这个读写分离的规则修改成改变之后的
导入对应的maven坐标
xml
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>在配置文件中配置读写分离规则,并配置允许bean定义覆盖配置项
配置项可能会爆红,但是不影响影响项目启动,是IDEA的问题
yaml
spring:
shardingsphere:
datasource:
names:
# 这里的master和slave并不是写死的,但是需要跟下面的master和slave对应
# 定义了两个数据源,名叫master和slave
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
# 主库ip及连接的数据库名
url: jdbc:mysql://192.168.10.135:3306/reggie?serverTimezone=UTC&useSSL=false
username: root
# 我的数据库没有密码,所以这里注释了,有需要可以自己调整
# password: root
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
# 从库ip及连接的数据库名
url: jdbc:mysql://192.168.10.134:3306/reggie?serverTimezone=UTC&useSSL=false
username: root
# password: root
masterslave:
# 读写分离配置
# 负载均衡:配置的是从库的负载均衡策略(轮询策略)
# 轮询:从库可以有多个,假设有3个从库,第一次走sql查询就是走1号库,第二次走2号,这样以此类 推,直到走完之后再次重复一遍,说白了就是按顺序来
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 指定主库数据源名称
master-data-source-name: master
# 指定从库数据源名称列表,多个从库用逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false,就是在控制台可以输出sql
# 配置允许bean定义覆盖配置项
main:
allow-bean-definition-overriding: true测试一下,主要检查的查询语句是不是由从库发出,以及增删改操作是不是由主库发出即可
最后我们将代码上传到github,
然后合并到master分支
如何合并?
先回到master分支,点一下master然后checkout就可以切回去了
然后选中v1.0,选中Merge,合并到master
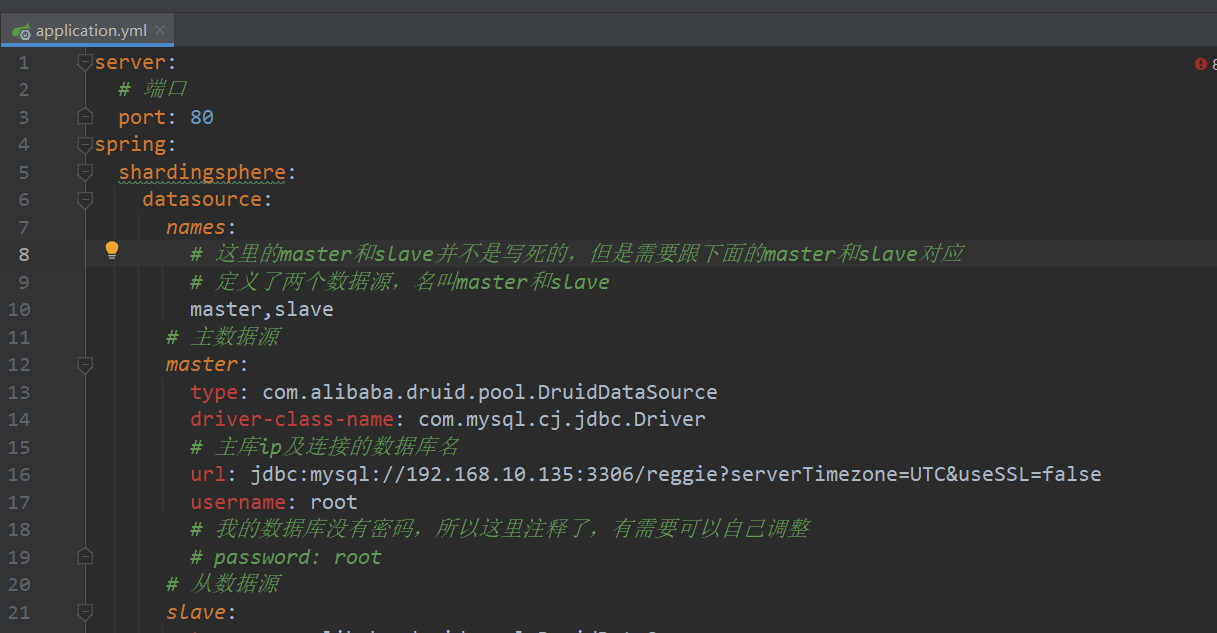
查看master分支下的yml配置文件,发现已经更新了
Nginx
简介
Nginx的下载和安装
Nginx是C语言开发的,所以需要先安装依赖
bash
yum -y install gcc pcre-devel zlib-devel openssl openssl-devel安装时遇到一个问题:Another app is currently holding the yum lock; waiting for it to exit...
说是另一个应用程序目前持有yum锁;等待它退出
解决方法:
bash
# 强行解除锁定
rm -rf /var/run/yum.pid
# 再次yum安装下载Nginx安装包
这里我去了nginx官网查看了现在的稳定版本,现在是1.24.0所以我也选择1.24.0

bash
wget https://nginx.org/download/nginx-1.24.0.tar.gz可以使用命令行方式,你也可以通过在Windows下载好之后传上来,我是直接上传了
解压,放在`/usr/local`目录下
bash
tar -zxvf nginx-1.24.0.tar.gz -C /usr/local/进入到我们解压完毕后的文件夹内
bash
cd /usr/local/nginx-nginx-1.24.0/创建安装路径文件夹
bash
mkdir /usr/local/nginx安装前检查工作
使用nginx-nginx-1.24.0目录下的configure来指定安装目录(不是真正的安装,只是安装前的检查工作)
bash
./configure --prefix=/usr/local/nginx编译并安装
bash
make && make installNginx目录结构
可以使用一个命令来展示当前目录下的内容
先安装这个tree
bash
yum install tree再输入`tree`
以树形结构来展示当前目录下的所有内容
Nginx配置文件结构
注意:http块中可以配置多个Server块,每个Server块中可以配置多个location块
bash
worker_processes 1; <-- 全局块
events { <-- events块
worker_connections 1024;
}
http { <-- http块
include mime.types; <-- http全局块
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server { <-- Server块
listen 80; <-- Server全局块
server_name localhost;
location / { <-- location块
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}Nginx命令
查看版本
bash
[root@localhost sbin]# ./nginx -v
nginx version: nginx/1.24.0检查配置文件正确性
进入sbin目录,输入`./nginx -t`,如果有错误会报错,而且也会记录日志
一般在启动Nginx服务之前检查
bash
[root@localhost sbin]# ./nginx -t
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful启动和停止
进入sbin目录,输入`./nginx`,启动完成后查看进程
bash
[root@localhost sbin]# ./nginx
[root@localhost sbin]# ps -ef | grep nginx
root 13485 1 0 19:36 ? 00:00:00 nginx: master process ./nginx
nobody 13486 13485 0 19:36 ? 00:00:00 nginx: worker process
root 13496 9863 0 19:36 pts/1 00:00:00 grep --color=auto nginx如果想停止Nginx服务,输入`./nginx -s stop`,停止服务后再次查看进程
bash
[root@localhost sbin]# ./nginx -s stop
[root@localhost sbin]# ps -ef | grep nginx
root 13499 9863 0 19:37 pts/1 00:00:00 grep --color=auto nginx重新加载配置文件
重新加载配置文件
上面的所有命令,都需要我们在sbin目录下才能运行,比较麻烦,所以我们可以将Nginx的二进制文件配置到环境变量中,这样无论我们在哪个目录下,都能使用上面的命令
使用`vim /etc/profile`命令打开配置文件,并配置环境变量,保存并退出
这个需要配置jdk的环境,记得改成自己的
bash
JAVA_HOME=/usr/local/jdk1.8.0_212
PATH=/usr/local/nginx/sbin:$JAVA_HOME/bin:$PATH之后重新加载配置文件,使用`source /etc/profile`命令,然后我们在任意位置输入`nginx`即可启动服务,`nginx -s stop`即可停止服务
bash
[root@localhost jdk1.8.0_212]# vim /etc/profile
[root@localhost jdk1.8.0_212]# source /etc/profile
[root@localhost jdk1.8.0_212]# nginx
[root@localhost jdk1.8.0_212]# ps -ef | grep nginx
root 13942 1 0 19:51 ? 00:00:00 nginx: master process nginx
nobody 13943 13942 0 19:51 ? 00:00:00 nginx: worker process
root 13945 9863 0 19:51 pts/1 00:00:00 grep --color=auto nginx
[root@localhost jdk1.8.0_212]# nginx -s stop
[root@localhost jdk1.8.0_212]# ps -ef | grep nginx
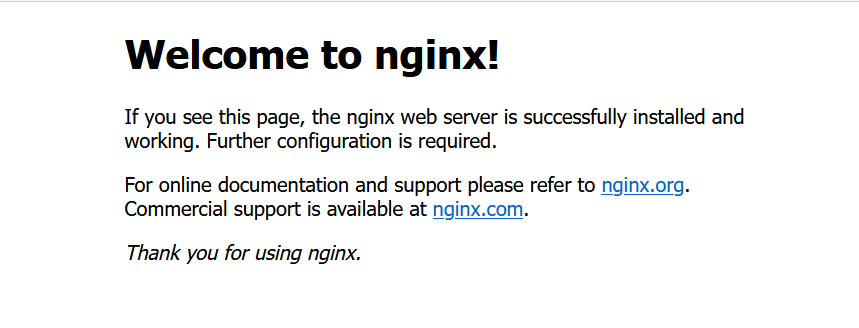
root 13956 9863 0 19:52 pts/1 00:00:00 grep --color=auto nginx查看自己IP,启动服务后,浏览器输入ip地址就可以访问Nginx的默认页面
如果发现自己连不上Nginx的话,可能是防火墙的问题,这里我也遇到了这个问题,所以我们需要开放80端口,并重启防火墙
bash
firewall-cmd --zone=public --add-port=80/tcp --permanentbash
systemctl restart firewalld.service重启完成后,在浏览器中输入ip即可访问
Nginux具体应用
部署静态资源
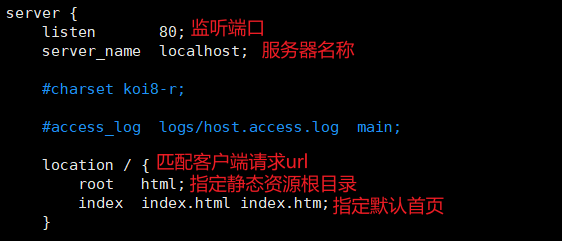
反向代理
正向代理
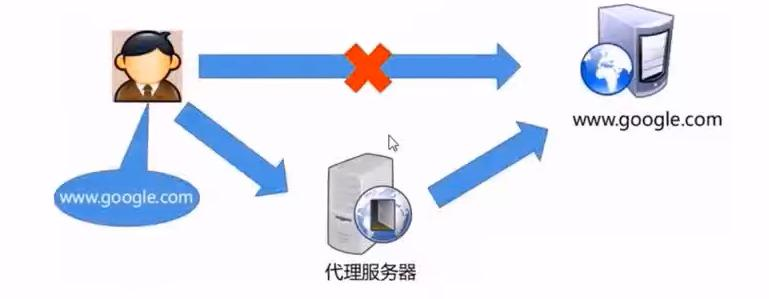
总结一下正向代理,其实很好理解,客户端直接访问原始服务器是访问不到的,得依靠代理服务器来访问,所以客户端需要先向代理服务器发送请求来指定原始服务器,然后代理服务器向原始服务器转交请求,原始服务器将内容发给代理服务器,再依靠代理服务器来返回给客户端
反向代理
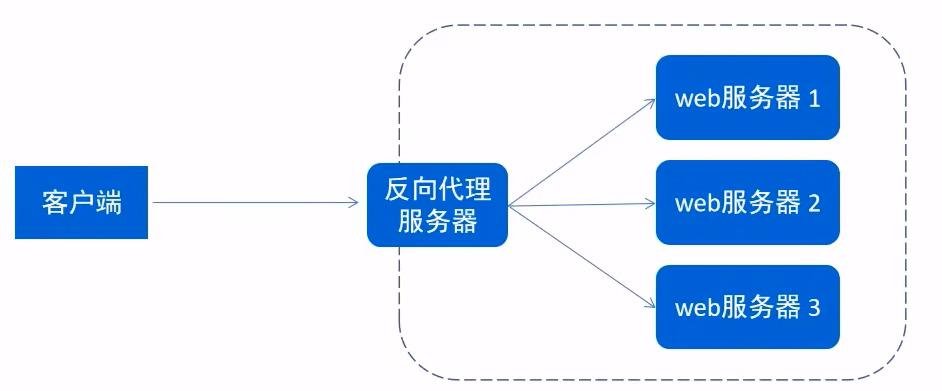
简单来说,正向代理是:(客户端+代理服务器)访问(web服务器),, 反向代理是:(客户端)访问(代理服务器+web服务器)
反向代理直接访问的是代理服务器,然后让代理服务器去web服务器里转发给你
配置反向代理
properties
server {
listen 82;
server_name localhost;
location / {
# 监听82端口,访问82端口则代理转发到下面的地址
proxy_pass http://IP地址:端口号;
}
}负载均衡
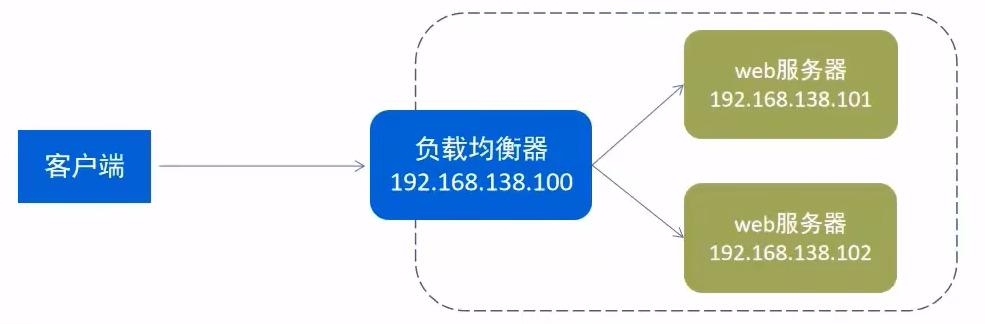
配置负载均衡
默认是轮询算法,第一次访问是`IP地址1`,第二次访问是`IP地址2`
也可以改用权重方式,权重越大,几率越大,现在的访问三分之二是第一台服务器接收,三分之一是第二台服务器接收
`server IP地址1 weight=10`
`server IP地址2 weight=5`
proxy_pass要与targetServer一致
properties
upstream targetServer{
server IP地址1:端口号;
server IP地址2:端口号;
}
server {
listen 82;
server_name localhost;
location / {
proxy_pass http://targetServer;
}
}Nginx的特点
1. 跨平台:Nginx可以在大多数操作系统中运行,而且也有Windows的移植版本
2. 配置异常简单:非常容易上手。配置风格跟程序开发一样,神一般的配置
3. 非阻塞、高并发:数据复制时,磁盘I/O的第一阶段是非阻塞的。官方测试能够支撑5万并发连接,在实际生产环境中跑到2-3万并发连接数(这得益于Nginx使用了最新的epoll模型)
4. 事件驱动:通信机制采用epoll模式,支持更大的并发连接数
5. 内存消耗小:处理大并发的请求内存消耗非常小。在3万并发连接下,开启的10个Nginx进程才消耗150M内存(15M*10=150M)
6. 成本低廉:Nginx作为开源软件,可以免费试用。而购买F5 BIG-IP、NetScaler等硬件负载均衡交换机则需要十多万至几十万人民币
7. 内置健康检查功能:如果Nginx Proxy后端的某台Web服务器宕机了,不会影响前端访问。
8. 节省带宽:支持GZIP压缩,可以添加浏览器本地缓存的Header头。
9. 稳定性高:用于反向代理,宕机的概率微乎其微。
前后端分离开发
问题说明
介绍
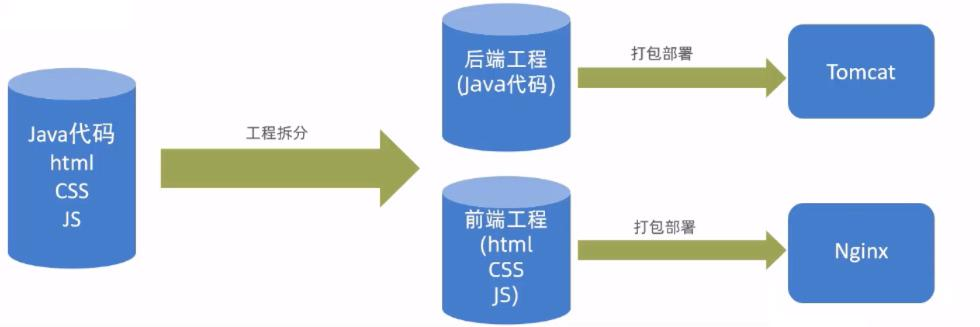
开发流程
YApi
介绍
Api是高效、易用、功能强大的api管理平台,旨在为开发、产品、测试人员提供更优雅的接口管理服务。可以帮助开发者轻松创建、发布、维护API,YApi还为用户提供了优秀的交互体验,开发人员只需要利用平台提供的接口数据写入工具以及简单的点击操作就可以实现接口的管理。
YApi让接口开发更简单高效,让接口的管理更具有可读性、可维护性,让团队协作更合理。
Git仓库:`https://github.com/YMFE/yapi`
使用
使用YApi,可以执行下面操作:
这个后期看看文档自学一下即可
Swagger
介绍
使用方式
1. 导入对应的maven坐标
xml
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>导入knife4j相关配置,并配置静态资源映射,否则接口文档页面无法访问,注意将controller的包路径修改为你自己的
java
@Configuration
@Slf4j
@EnableSwagger2
@EnableKnife4j
public class WebMvcConfig extends WebMvcConfigurationSupport {
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("开始进行静态资源映射...");
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/");
registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
registry.addResourceHandler("doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
//设置对象转化器,底层使用jackson将java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
//将上面的消息转换器对象追加到mvc框架的转换器集合当中(index设置为0,表示设置在第一个位置,避免被其它转换器接收,从而达不到想要的功能)
converters.add(0, messageConverter);
}
@Bean
public Docket createRestApi() {
//文档类型
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("com.eastwind.controller"))
.paths(PathSelectors.any())
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("瑞吉外卖")
.version("1.0")
.description("瑞吉外卖接口文档")
.build();
}
}在拦截器在中设置不需要处理的请求路径
java
//定义不需要处理的请求
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**",
"/common/**",
//对用户登陆操作放行
"/user/login",
"/user/sendMsg",
"/doc.html",
"/webjars/**",
"/swagger-resources",
"/v2/api-docs"
};启动服务,访问 `http://localhost/doc.html` ,我这里的端口号用的80,根据自己的需求改,运行之前记得把linux的服务开起来
这里我启动时报了一个异常,
Failed to start bean 'documentationPluginsBootstrapper'; nested exception is java.lang.NullPointerException
springboot 升级到 2.6.0之后,swagger版本和springboot出现了不兼容情况,因为SpringBoot处理映射匹配的默认策略发生变化:请求路径与 Spring MVC 处理映射匹配的默认策略已从AntPathMatcher更改为PathPatternParser
在application.yml中配置,加在spring的下面,注意层级关系
yaml
mvc:
pathmatch:
matching-strategy: ant_path_matcher访问接口文档
此时就显示出来了
常用注解
加上这些注解,可以将我们生成的接口文档更规范,具体使用效果可以看看文档,这里不做太多介绍
项目部署
配置环境说明
一共需要三台服务器
在服务器A中安装Nginx,将前端项目`打包`目录上传到Nginx的html目录下
修改Nginx配置文件nginx.conf,新增如下配置
properties
server {
listen 80;
server_name localhost;
location / {
root html/dist;
index index.html;
}
location ^~ /api/ {
rewrite ^/api/(.*)$ /$1 break;
proxy_pass http://192.168.10.134;
}
}在服务器B中安装JDK,Git,MySql
将项目打成jar包,手动上传并部署(当然你也可以选择git拉取代码,然后shell脚本自动部署)
部署完后端项目之后,我们就能完成正常的登录功能了,也能进入到后台系统进行增删改查操作